
A few days ago, I created a post about Convert Audio and Video to Text with Sonix AI, that is not a sponsored post anyway, I just shared what I experienced with 😁
After got Google Cloud Platform credits yesterday, i want to try different way to transcribe video to text, with Speech To Text on GCP.
First, we have to create a Compute Engine VM instance with scopes :
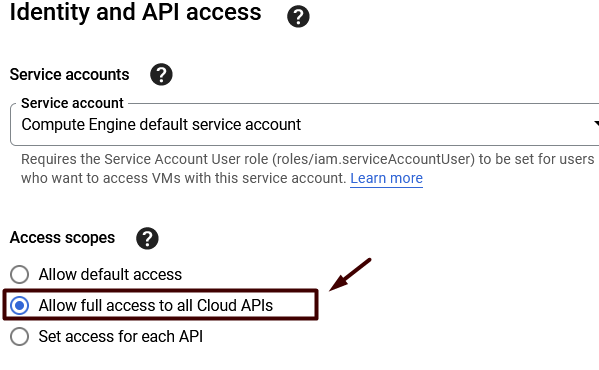
Cloud API access scopes : Allow full access to all Cloud APIs
and then upload the video to your Compute Engine VM, its easy if we use SSH-in-browser, just click the ⬆️and then choose the files you want to upload.

Extract Audio (mp3) from Video
install ffmpeg first with command :
sudo apt install ffmpegthen we start to extract video to audio by this command :
ffmpeg -i wego-head.mp4 wego-head.mp3Results :
ariq@instance-1:~$ ffmpeg -i wego-head.mp4 wego-head.mp3
ffmpeg version 3.4.11-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 7 (Ubuntu 7.5.0-3ubuntu1~18.04)
configuration: --prefix=/usr --extra-version=0ubuntu0.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --enable-gpl --disable-stripping --enable-avresample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librubberband --enable-librsvg --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzmq --enable-libzvbi --enable-omx --enable-openal --enable-opengl --enable-sdl2 --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libopencv --enable-libx264 --enable-shared
libavutil 55. 78.100 / 55. 78.100
libavcodec 57.107.100 / 57.107.100
libavformat 57. 83.100 / 57. 83.100
libavdevice 57. 10.100 / 57. 10.100
libavfilter 6.107.100 / 6.107.100
libavresample 3. 7. 0 / 3. 7. 0
libswscale 4. 8.100 / 4. 8.100
libswresample 2. 9.100 / 2. 9.100
libpostproc 54. 7.100 / 54. 7.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'wego-head.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
encoder : Lavf54.29.104
Duration: 00:00:26.75, start: 0.000000, bitrate: 760 kb/s
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p(tv, bt709), 1280x720 [SAR 1:1 DAR 16:9], 624 kb/s, 23.98 fps, 23.98 tbr, 24k tbn, 47.95 tbc (default)
Metadata:
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 128 kb/s (default)
Metadata:
handler_name : SoundHandler
Stream mapping:
Stream #0:1 -> #0:0 (aac (native) -> mp3 (libmp3lame))
Press [q] to stop, [?] for help
Output #0, mp3, to 'wego-head.mp3':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41
TSSE : Lavf57.83.100
Stream #0:0(und): Audio: mp3 (libmp3lame), 44100 Hz, stereo, fltp (default)
Metadata:
handler_name : SoundHandler
encoder : Lavc57.107.100 libmp3lame
size= 419kB time=00:00:26.75 bitrate= 128.2kbits/s speed=52.9x
video:0kB audio:418kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.083098%Send a Request
Before we use python3 to send a request, we should install python3-pip first on our Compute Engine VM
sudo apt install python3-pipand install google-cloud-speech package too
sudo pip3 install google-cloud-speechCreate and edit speech.py file :
nano speech.pyand use the following code to send a transcription request to Speech-to-Text (python codes are provided by google).
#!/usr/bin/env python
# Copyright 2017 Google Inc. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Google Cloud Speech API sample that demonstrates how to select the model
used for speech recognition.
Example usage:
python transcribe_model_selection.py \
resources/Google_Gnome.wav --model video
python transcribe_model_selection.py \
gs://cloud-samples-tests/speech/Google_Gnome.wav --model video
"""
import argparse
# [START speech_transcribe_model_selection]
def transcribe_model_selection(speech_file, model):
"""Transcribe the given audio file synchronously with
the selected model."""
from google.cloud import speech
client = speech.SpeechClient()
with open(speech_file, "rb") as audio_file:
content = audio_file.read()
audio = speech.RecognitionAudio(content=content)
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.ENCODING_UNSPECIFIED,
sample_rate_hertz=16000,
language_code="ja-JP",
model=model,
)
response = client.recognize(config=config, audio=audio)
for i, result in enumerate(response.results):
alternative = result.alternatives[0]
print("-" * 20)
print("First alternative of result {}".format(i))
print(u"Transcript: {}".format(alternative.transcript))
# [END speech_transcribe_model_selection]
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description=__doc__, formatter_class=argparse.RawDescriptionHelpFormatter
)
parser.add_argument("path", help="File or GCS path for audio file to be recognized")
parser.add_argument(
"--model",
help="The speech recognition model to use",
choices=["command_and_search", "phone_call", "video", "default"],
default="default",
)
args = parser.parse_args()
if args.path.startswith("gs://"):
transcribe_model_selection_gcs(args.path, args.model)
else:
transcribe_model_selection(args.path, args.model)On this post, I want to transcribe an intro of japanese song (early 00:00 to 00:26), so I set language_code="ja-JP" on this case.
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.ENCODING_UNSPECIFIED,
sample_rate_hertz=16000,
language_code="ja-JP",
model=model,
)
Run speech.py to start transcribe audio to text with this command :
python3 speech.py wego-head.mp3Result
After we run that command, we can see the output :

ariq@instance-1:~$ python3 speech.py wego-head.mp3
--------------------
First alternative of result 0
Transcript: かつてこの世の全てを手に入れた伝説の海賊王ゴールドロジャー彼の死に際に放った一言は人々を海へと駆り立てた俺の財宝か欲しけりゃくれてやる探せこの世の全てをそこに置いてきた人々はロマンを追い求めるI also have transcribe it too with Sonix AI
Results between Speech-to-Text GCP and Sonix AI.
| Speech-to-Text GCP | Sonix AI |
|---|---|
| かつてこの世の全てを手に入れた伝説の海賊王ゴールドロジャー彼の死に際に放った一言は人々を海へと駆り立てた俺の財宝か欲しけりゃくれてやる探せこの世の全てをそこに置いてきた人々はロマンを追い求める | かつてこの世のすべてを手に入れた伝説の海賊を、ゴールドロジャーは彼の死に際に放った。一言は人々を海へと駆り立てた往年の財宝欲しけりゃくれてやるんだ探すこの世のすべてをそこに置いてきた人々は、ロマンを追い求める様はまさに大海賊時代。 |
That's it.
Anyway thanks Google for provide me free credits on GCP,
and thanks Sonix AI for free 30 minutes too 😊🤙
Source :
- Speech to Text -> Transcribe Videos Docs
- (python code) Speech to Text -> Python transcribe.py
- Sonix AI
- Full song : One Piece Opening 15 WE GO